


After a few months at Exeon and having previously mostly focused on building static behavior detections, I share some insights regarding distinct properties for detection engineering based on machine learning algorithms. It ultimately changes how we approach building detections and which questions must be answered during development.
We, at Exeon, leverage machine learning algorithms and its baselining capabilities for our NDR (Network Detection and response) platform of Exeon. The application of ML ranges from detections for domain generation algorithms to traffic volume analytics, command-and-control channel detections and detecting lateral movement. We wrote about the general benefits of using ML in the previous blog post The Future of Network Security: Predictive Analytics and ML-Driven Solutions.
Besides the general discussion about the benefits and challenges of using machine learning algorithms for threat detection, detection engineers face their own benefits and challenges when building detections. In this blog post, these aspects are outlined from a detection engineer’s perspective and the corresponding questions that come up during use case development.
Detection engineering is the process of identifying relevant threats and developing, improving, verifying and tuning detections to defend against those threats.
What does it mean to use ML algorithms for detection engineering?
Until recently and still today, many security teams rely on static signatures for threat detection. Either using an IDS for network analysis or static behavior detections based on endpoint logs. IoCs, IoAs, Yara or Sigma rules are all used to find malicious behavior.
With more and more data, it gets difficult to catch up with everything and it gets difficult to cover all sources and attack patterns with individual rules. To come up with these challenges, machine learning algorithms help in switching the perspective during detection engineering. When we use ML, we are able to learn the good state and detect deviations.
Supervised and unsupervised Machine Learning algorithms
Machine learning algorithms can be split into two groups, the supervised and the unsupervised algorithms. Both have advantages and some constraints in their application.
- The supervised algorithms will be pre-trained in advance to recognize known-good and detect known-bad characteristics. Using unsupervised algorithms, we define some important characteristics to watch for and learn that baseline inside the network to detect outliers without static known-bad indicators.
- Unsupervised algorithms use baselining, that means, learning the good state of the infrastructure. They can dynamically adapt their baseline to customers’ environments. In our context, we focus on network communication and then find outliers or unusual behavior, which deviates from the normal state. At the end, it all comes down to (network) statistics, calculation of probabilities, time-analysis and clustering (considering peer groups).
So, the first question will always be whether we use supervised or unsupervised machine learning. Both have advantages for their application, and these must be evaluated during development.

How detection engineering using ML needs a rephrasing of questions
Detection engineering relying on machine learning algorithms needs a rephrasing of important questions during use case development. For many use cases, we switch the perspective from what is malicious to what normal looks like. This allows being more open to variations in malicious behavior. We don’t go to the doctors daily, but spot changes in our body temperature, tiredness and so on compared to the normal state.
From time to time, making an in-depth check is needed though, like a compromise assessment in IT security. Therefore, detection engineers must understand similarities between attack patterns, the characteristics of them and the baseline for which outliers must be detected. In contrast to traditional detection approaches, it’s more about understanding what is good and normal than just focusing on what is bad. In summary, understanding the context and the baseline of a system or infrastructure makes detection more robust.
Detection engineering relying on machine learning algorithms needs a rephrasing of important questions during use case development. In contrast to traditional detection approaches, it’s more about understanding what is good, than just focusing on what is bad. Knowing the baseline will allow finding the outliers.
Now, I will provide some insights about some aspects during use case development and what questions we face when we use unsupervised machine learning. In addition, an example for internal user enumeration through LDAP is given.
- Setting the goal: We have to define the goal of a detection use case by explicitly defining the attack pattern we would like to monitor. Example: In some specific network segments only a subset of network services is used on a regular basis. We want to learn how many LDAP requests are made usually and detect changes compared to this normal state.
- Extract characteristics to learn the baseline: We must study and understand the characteristics of the use case we would like to detect (same as in traditional detection engineering). Then go further by studying the baseline, the common good known state and extract the properties for the algorithms to learn the good normal state to be able to alert on outliers (malicious behavior). We don’t have to define what exactly the threshold is but just define the parameters to learn that baseline.
- Define the comparison model: We must decide whether we need to trigger an anomaly based on a comparison between the current behavior of one client to its past or detecting outliers of one client when comparing its behavior with its peers (reference group). We can define popularity thresholds, meaning, if and how other clients’ behavior should be considered during analysis.
- Define the learning window: An important factor is what the time window should be for the learning phase, the period to learn the good state so to speak. The time window has direct impact on the variability of the learned behaviour.
To speed up detection engineering, for example, new unsupervised detections can be built using generic use case framework which provides ML features in a more accessible way to detection engineers without having to be a ML developer.
How to make the life of security analysts easier
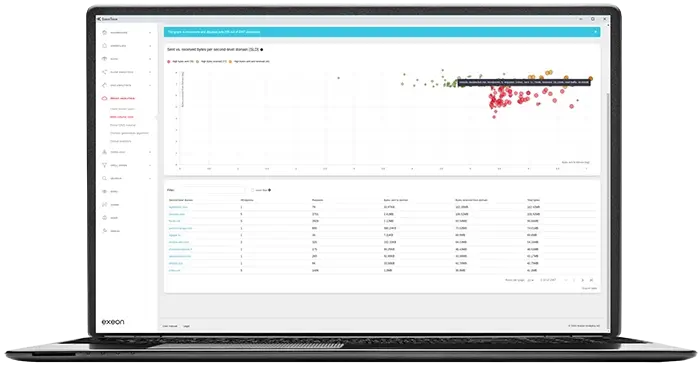
Furthermore, detection engineers and ML development teams must keep in mind what it means for cyber security analysts looking at the alerts and anomalies triggered by these algorithms.
Here, the explanation of anomalies is of utmost importance. Today, security tools sometimes only provide some information that the ML engine detected XY, but it’s unknown to the analysts what exactly was detected. In Exeon.NDR, we provide the needed information in various places, either providing always the exact algorithm name and context information about an anomaly or the baselining information directly on the anomaly.
Where customers can use ML for their own detection
Internally, we are able to use supervised and unsupervised algorithms, while customers are able to use unsupervised algorithms for their own detection testing. Exeon’s AI security platform provides a powerful outlier detection feature for which customers must only provide what data points should be considered and get anomalies for all outliers.
What ML algorithms mean for testing and verification
One important aspect of detection engineering is the testing and verification phase of new detections. And here is another aspect which is very different to traditional detection testing. Until now, we were able to run tests against specific evidence or log information and got direct feedback: “bad” vs “not bad”, “found” vs. “not found”.
When it comes to machine learning algorithms and the use of timing differences, clustering, popularity, context and multiple characteristics, the testing of ML algorithms is a challenge by itself. Therefore, good datasets using real data or synthetic data are required to build the needed baseline which tests can be built on.
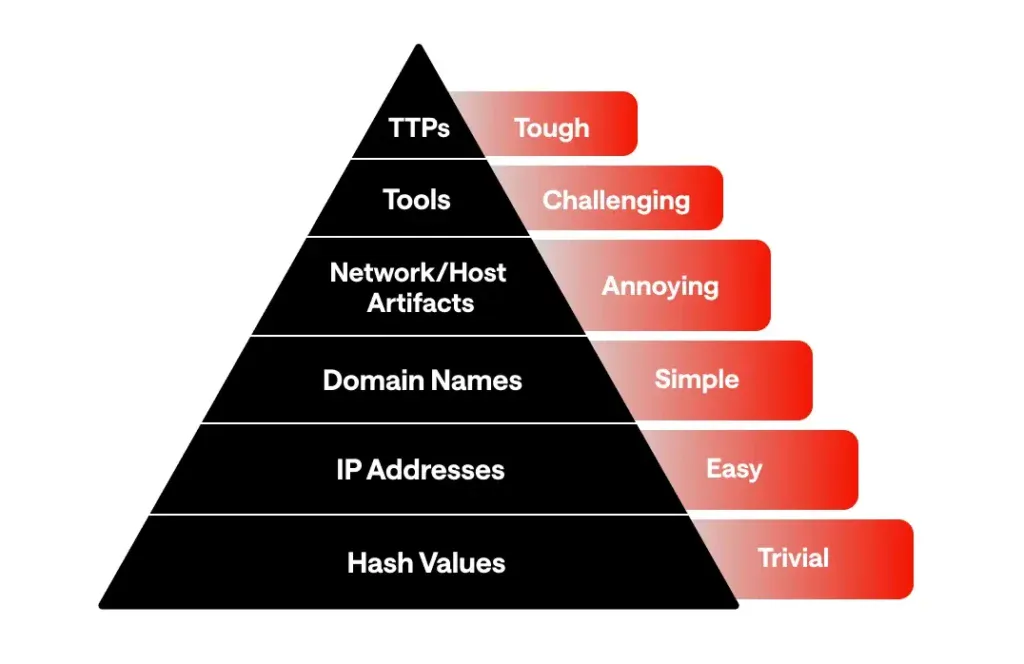
Source: David J. Bianco
Using the Pyramid of Pain, robust machine learning algorithms will target the top of the pyramid, but in regard to the detection testing, it’s also on the top, meaning it is more difficult compared to traditional detection testing.
In summary, detection engineering using machine learning algorithms go beyond the traditional detection engineering approach of focusing on known bad, but on learning the known-good baseline (good health state) and focusing on how we can leverage this baseline to alert on abnormal behavior. The questions detection engineers face are different during development, but providing a good ML framework will make it more accessible to detection engineers and customers’ security teams.
ML-Driven threat detection in action
Hence, the Swiss-made network security solution Exeon.NDR provides the full picture on good and bad behaviors, as it is based on ML algorithms that are especially built for the analysis of encrypted data – which cannot be analyzed with traditional Network Detection & Response (NDR) solutions.
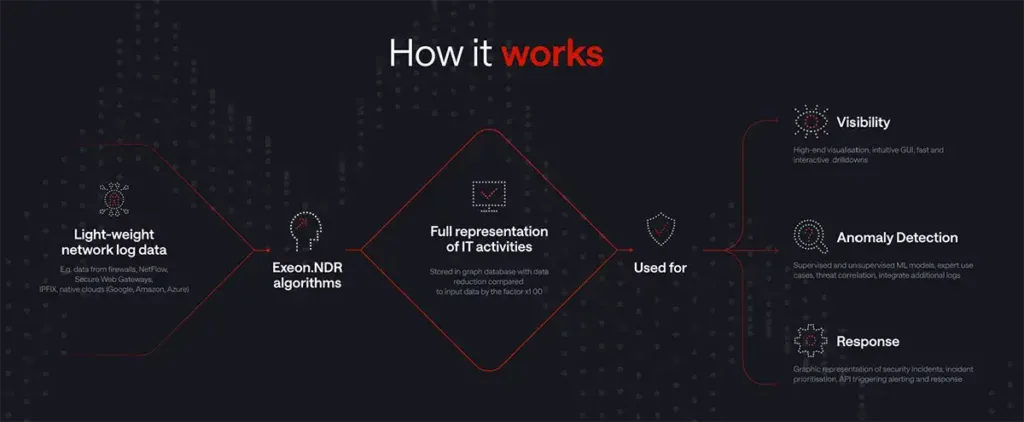
By utilizing advanced ML algorithms that analyze network traffic and application logs, Exeon offers organizations quick detection and response to even the most sophisticated cyberattacks.
Book a free demo to discover how Exeon.NDR leverages ML algorithms to make your organization more cyber resilient – quickly, reliably, and completely hardware-free.